

Background
In today's financial sector, the manual extraction of Key Performance Indicators (KPIs) from annual reports represents a significant operational bottleneck. Financial institutions process thousands of reports annually, each containing critical metrics buried within complex document structures. This process traditionally requires substantial human effort, is prone to errors, and struggles to scale with increasing document volumes.
Our team faced several critical challenges:
-
Document format variability: Reports exist in both digital PDF and scanned formats, each requiring different processing approaches
-
Data consistency: KPIs appear in various formats and units across different reports
-
Accuracy requirements: Financial data extraction demands near-perfect precision
-
Scale: Processing hundreds of documents while maintaining consistent accuracy
To address these challenges, we developed a pipeline leveraging modern AI capabilities while ensuring practical deployability. The goal was clear: create a reliable, automated system for KPI extraction that could seamlessly integrate with existing financial dashboards while maintaining high accuracy standards.
In this first part of the case study, we focus on the infrastructure and cost-optimization strategies that make this pipeline production-ready on Ryax. Part 2 will dive into the retrieval-augmented generation (RAG) system that powers the KPI extraction itself.
")
Above is the Ryax studio interface showing an 8-step sequential workflow, from "Emit Every" to "PROD Update KPIs on DB", demonstrating the end-to-end automation pipeline for KPI extraction.
Ryax Benefits: Unlocking New Possibilities and Optimizations for fintech applications
Through practical implementation, we discovered several key advantages of using Ryax for this financial data processing pipeline:
-
Simplicity and flexibility: Our engineering team leveraged Ryax's abstraction layers to rapidly prototype and iterate on the KPI extraction workflow. The modular architecture allowed us to:
-
Swap out and test different OCR engines without pipeline reconstruction
-
Implement custom preprocessing steps for different document types
-
Add validation stages without disrupting existing processing steps
-
-
Enhanced productivity: the platform's unified development and deployment environment significantly reduced operational overhead:
-
Single platform for both development and production environments
-
Integrated monitoring and logging across all processing stages
-
Direct deployment capabilities eliminating DevOps complexity
-
Version control and reproducibility built into the workflow system
-
-
Seamless efficiency and scalability: the architecture proved particularly valuable for our distributed processing needs:
-
Multi-site deployment supporting data locality requirements
-
Cross-cloud provider compatibility addressing regulatory requirements
-
GPU resource optimization for cost-effective processing
-
Automatic workload distribution based on available resources
-
-
Cost-effective operations: our implementation leverages key Ryax platform capabilities to optimize resource utilization and reduce operational costs:
-
On-demand GPU allocation: Ryax's serverless architecture automatically allocates GPU resources only when the vision-language models (Qwen2-VL, ColPali) are actively processing documents
-
Multi-tenant execution resource sharing: Multiple extraction pipelines can efficiently share GPU resources through Ryax's orchestration layer
-
Automated cleanup: Resources are immediately released after processing, eliminating idle GPU costs
-
VPA-pilot: VPA-pilot: An AI-driven resource optimization system that continuously monitors container resource utilization patterns and automatically adjusts CPU, memory, and GPU allocations based on actual usage. This dynamic vertical pod autoscaling ensures containers receive precisely the resources they need, preventing both over-provisioning and performance bottlenecks through real-time adaptation.
-
Our implementation leverages Ryax's modular workflow architecture to achieve efficient resource management in AI processing. The platform's visual pipeline design enables clear separation of concerns, dividing our extraction process into distinct actions with varying resource requirements. This granular approach allows the system to intelligently allocate resources - particularly valuable for GPU utilization in our vision-language models (Qwen2-VL, ColPali).
Key efficiency gains come from:
-
Selective GPU allocation for vision-intensive tasks while running CPU-bound operations (PDF extraction, data formatting) on standard compute resources
-
Automated resource cleanup and reallocation between workflow stages
-
Built-in data persistence and logging capabilities eliminating need for separate storage management
The workflow execution automatically adapts to processing demands through dynamic batching and memory management. For instance, our PDF processing pipeline adjusts image resize factors based on available GPU memory, while maintaining all intermediate results and execution logs for debugging and optimization. This comprehensive observability helps engineering teams track performance and resource utilization across different document types and workloads.
The results demonstrate consistent 40-50% accuracy on both clean and scanned PDFs, achieved through efficient resource utilization rather than brute-force GPU allocation. By leveraging Ryax's infrastructure, engineering efforts can focus on improving extraction accuracy while the platform handles resource optimization, data persistence, and execution monitoring.
Discussion: Cost-optimizations for AI deployments
As part of automated pipeline for financial KPI extraction, we implemented a containerized, multi-step workflow on Ryax designed to distributed computational resources on processing needs. Each action within the pipeline is executed in a dedicated container, ensuring modular processing and optimal resource utilization.
The following table outlines the CPU, GPU and memory consumption for each of the key actions in the workflow. While most steps rely solely on CPU processing, certain LLM tasks (like ColPali document indexing and Vision Inference) need GPU acceleration.

To estimate the cost of running our 8 step workflow on a single virtual machine (VM) in both Amazon Web Services (https://aws.amazon.com/pricing) and Google Cloud Platform (https://cloud.google.com/pricing), we need to identify VM instances that meet the highest resource demands of our workflow. Given that Actions 5 and 6 require GPU acceleration and substantial memory, we’ll focus on instances equipped with NVIDIA H100 GPUs, which offer 80 GB of GPU memory.
AWS offers the p5.48xlarge instance, which includes 8 NVIDIA H100 GPUs, each with 80 GB of memory, totaling 640 GB of GPU memory. This configuration provides ample resources to accommodate the GPU and memory requirements of Actions 5 and 6. The p5.48xlarge instance is priced at approximately $98.32 per hour.
GCP provides the a3-highgpu-8g instance, featuring 8 NVIDIA H100 GPUs, each with 80 GB of memory, totaling 640 GB of GPU memory. This instance is priced at approximately $88.49 per hour.
The total execution time for our workflow is 21 minutes. To calculate the cost, we determine the per-minute rate for each instance and multiply it by the total duration.
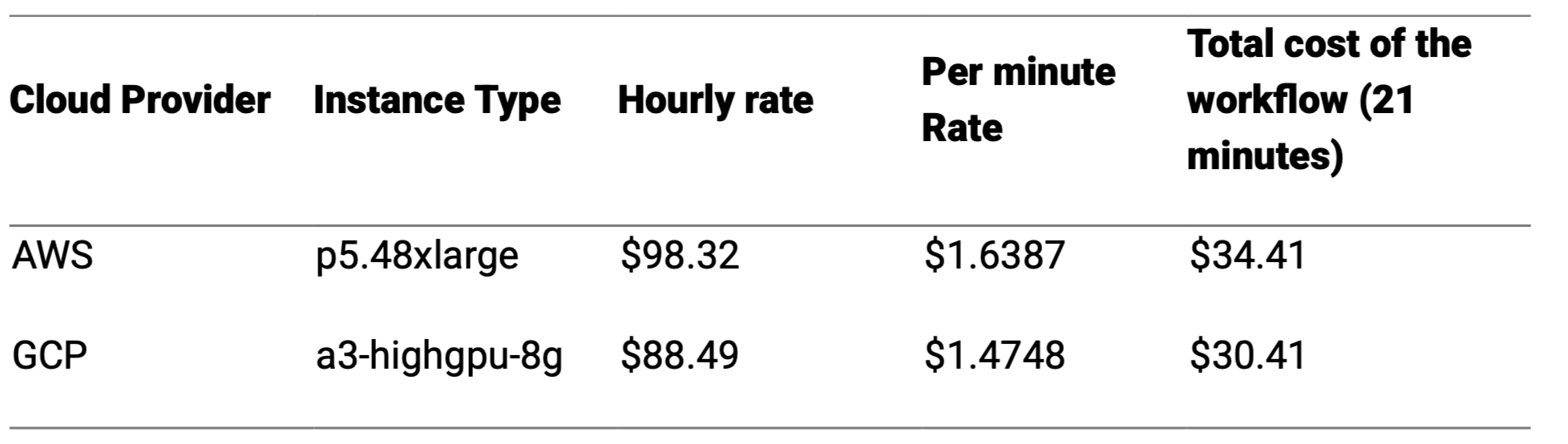
These exaggerated costs highlight a significant inefficiency: renting monolithic virtual machines (VMs) often leads to over-provisioning, as the allocated resources frequently exceed the actual requirements of individual workflow actions. This discrepancy results in elevated expenses, especially when high-end GPUs like the NVIDIA H100, equipped with 80 GB of memory, are underutilized during substantial portions of the workflow.
By leveraging platforms like Ryax, we can decompose the monolithic workflow into discrete actions, each with tailored resource allocations. This approach ensures that each action utilizes only the necessary resources, thereby optimizing both performance and cost.
Scaleway offers flexible pricing for various resources:
- vCPU with 4 GB RAM: Approximately €0.01 per hour.
- NVIDIA H100 GPU (80 GB): Approximately €2.73 per hour.
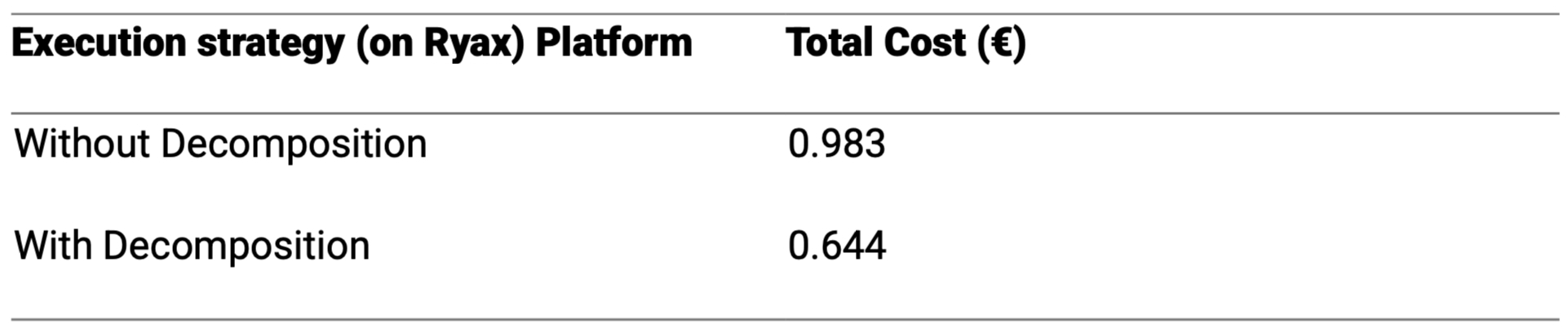
If we execute the entire 21-minute workflow on a single VM equipped with 8 vCPUs and an NVIDIA H100 GPU, the cost would be: €0.028 for vCPU and €0.955 for GPU.By decomposing the workflow and allocating resources per action: €0.001 (Actions 1-4, 7-8) + €0.369 (Action 5) + €0.274 (Action 6) ≈ €0.644.
By decomposing the workflow and allocating resources based on the specific needs of each action, the total execution cost is reduced from approximately €0.983 to €0.644. This represents a cost saving of about 34%. This analysis underscores the financial benefits of adopting a modular approach to workflow execution, ensuring that resources are provisioned efficiently and cost-effectively.
To optimize our workflow costs, we evaluated the use of inference-as-a-service for Actions 5 and 6, focusing on token-based pricing models. Processing an A4-sized image at 300 dpi generates approximately 88,000 tokens. Consequently, Action 5, which involves indexing a 500-page financial report, would consume around 44 million tokens, while Action 6, processing 66 images (22 sets of 3 images), would use about 5.9 million tokens.
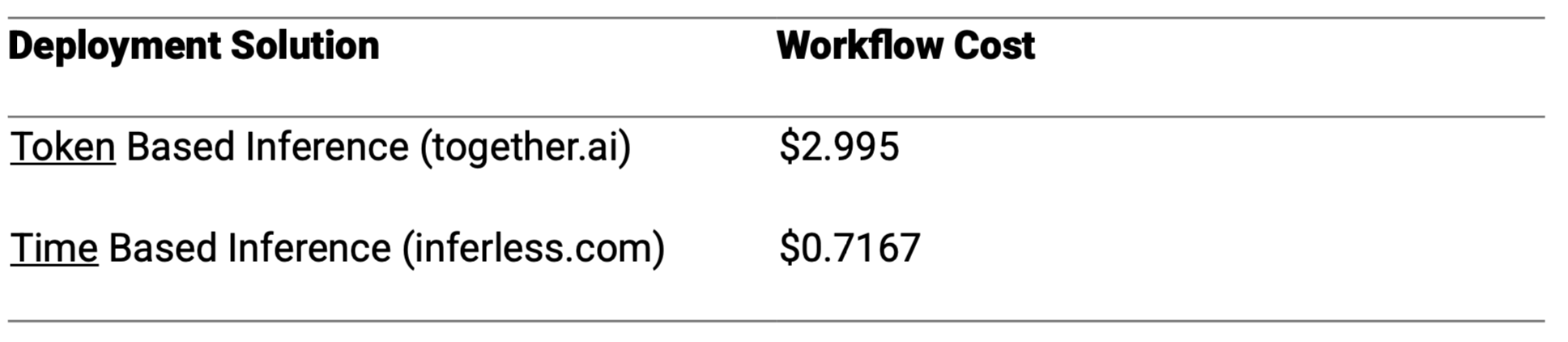
Together.ai charges 0.06 per million tokens, resulting in an inference cost of2.64 for Action 5 and 0.354 for Action 6. The combined cost for both actions is approximately2.994. For the remaining actions (1-4 and 7-8), the previously estimated cost remains around $0.001.
Exploring alternative inference services that bill per unit time, such as Inferless (www.inferless.com/pricing), presents a potential optimization opportunity. For example, utilizing a dedicated NVIDIA A100 GPU with 80 GB of memory costs approximately 0.001491 per second. In our workflow, Actions 5 and 6 have total durations of 8 and 6 minutes, respectively. After accounting for a 3-minute model loading time for each action, the effective inference times are 5 minutes (300 seconds) for Action 5 and 3 minutes (180 seconds) for Action 6. This results in costs of 0.4473 for Action 5 and 0.2684 for Action 6. Therefore, the combined inference cost for Actions 5 and 6 using Inferless is approximately 0.7157.
In summary, this study shows that breaking down a large AI workflow into smaller, separate tasks helps match resources to actual needs and saves money. By identifying steps that require a lot of resources, like those needing GPU acceleration, and carefully comparing different cloud pricing and new inference services, we can cut costs by about 34%. This approach highlights the importance of providing the right amount of resources. As AI applications grow, using smart management and flexible pricing will be key to maintaining both performance and cost-effectiveness.
While a 34% cost reduction may seem modest when considering a single workflow execution costing around €1, the impact becomes substantial when scaled across multiple runs. Our workflow processes annual financial reports for individual companies, extracting Key Performance Indicators (KPIs) specific to each year. For a comprehensive financial dashboard, we analyze data spanning a decade for numerous companies.

To date, we have executed this workflow 1,180 times. With each run originally costing approximately €0.983, the total expenditure amounts to about €1,160. Implementing a 34% cost reduction yields savings of approximately €0.334 per run, resulting in total savings of around €394 over the 1,180 executions. Given that the workflow runs every 45 minutes, totaling 32 times daily, this translates to daily savings of about €10.69 and monthly savings of approximately €320.85. Therefore, even seemingly modest percentage reductions can lead to significant financial benefits when applied at scale.
Conclusion
By decomposing the KPI extraction pipeline into modular actions on Ryax, we gained fine-grained control over compute, memory, and GPU usage, translating directly into predictable performance and measurable cost savings of around 34%. This infrastructure-first approach ensures that scaling to hundreds or thousands of financial reports does not require over-provisioned, monolithic GPU instances.
With these foundations in place, Part 2 of this case study focuses on the RAG-based KPI extraction pipeline itself, detailing how information retrieval, vision-language models, and human-in-the-loop validation work together to deliver accurate, production-grade financial insights.